
A guide to ML model serving

Rui Vasconcelos
on 17 May 2021
Tags: AI/ML , deep learning , Kubeflow , kubernetes , machine learning , MLOps
TL;DR: How you deploy models into production is what separates an academic exercise from an investment in ML that is value-generating for your business. At scale, this becomes painfully complex. This guide walks you through industry best practices and methods, concluding with a practical tool, KFServing, that tackles model serving at scale.
From training to model serving
If you are doing machine learning within an organization, chances are you are looking to build one of two types of system:
- Analytic system to make data-driven decisions
- Operational system to build data-powered products
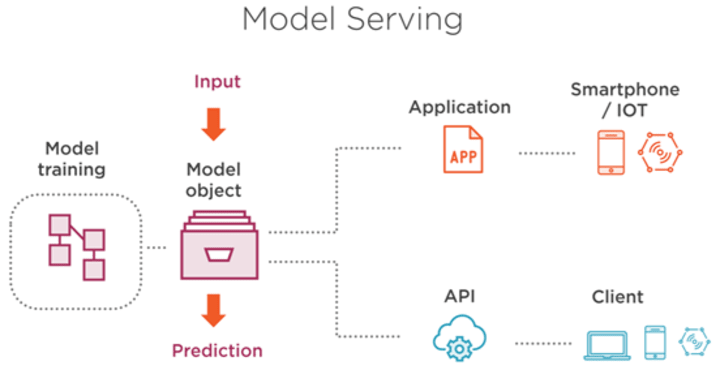
Training high accuracy models is only a small part of building the machine learning systems that will bring value to your organization. You want models that are great at predicting things, but that is not the end of your journey.
The training phase ends when you dump your model, simplistically an n-dimensional matrix of optimized weights, into:
- A binary file, e.g. .bin
- A human-readable object file, e.g. .json
Once you have a reasonably good model in a file, you are only about 20% done.
Your next big challenge is to allow your applications in production (analytic or operational) to make use of this model for inference, i.e. make predictions about new data.
The complexities of modern ML at scale
Traditionally, machine learning was reserved for academics who had the mathematical skills to develop complex algorithms and ML/DL models. However, experts in algorithms lacked knowledge on how to productize these models for consumption at scale.
With large market demand for deployment of models into production and lack of operations capabilities within traditional data science teams, an urge for cross-competency collaborative work (data science, data engineering, infrastructure and DevOps) and appropriate tools has arisen alongside a new field – MLOps.
Rather than a ship-and-forget pattern present in traditional software, machine learning systems require a lot of iteration loops and continuous improvement, as represented in the image below:

A few of the complexities of managing these modern AI systems include:
- Complex infrastructure (bare metal, virtualized cloud, container orchestration) with diverse hardware (CPU, GPU, DPU, TPU, FPGA, ASICs) and diverse environment needs – libs, frameworks.
- Multiple steps in the ML workflow with different requirements (e.g. fast compute for training, high bandwidth for data ingestion, low compute and lots of manual work in data preparation)
- Model lifecycle management – Unlike traditional software, machine learning models can not be deployed and forgotten, as new data may imply a need to check for model drift and automatically update it. Traceability of models in production becomes imperative.
- Compliance with current operations, not introducing completely new workflows for DevOps teams
- Organizational adaptation to this new shared-responsibility
All of this sums up to high technical debt and costly development cycles unless great processes, methodologies and tools are put in place.
Taking models into production
There are a few options when it comes to bringing your ML models into production.
Model embedded in the app
The most direct way to use your model within an application is called model embedding. In this method, you simply embed the file that contains your model within your application code, and the application will directly access it.
This has a few advantages, as the simpler infrastructure and direct access provide maximum performance during inference and, being embedded within the application, it allows for offline use. However, this is not a scalable method and generally regarded today as not a great practice.
Model served as an API
The most commonly used method today is model serving or model as a service.
This architecture effectively separates the application from the model through an API, simplifying organizational processes, model versioning and reuse, seamless updates with phased rollouts and hardware separation allowing the application and model server to have diverse hardware (CPU, GPU, FPGA) and independent scaling upon requests.
Modern MLOps platforms like Kubeflow only support Model as a Service architecture.
An alternative to embedding the model is to wrap a model binary file around a microservice (e.g. Python Flask app) that includes a method, class or library to make the model consumable by other applications.

This is difficult to manage and not very scalable, as the implementation is framework specific. You need to create a microservice that is compatible with the frameworks you intend to use in your end application, and there are dozens of them.
Model saved and used as a library
Finally, the best approach if you want something that can scale without a lot of growth pains is to use your model as data.
In this method, you save the model in a standardized way (e.g. Tensorflow SavedModel, PMML, PFA or ONNX) that is programmatically readable by any modern programming environment, language and framework, allowing reuse across diverse applications.

This can be a bit more challenging initially from a technical standpoint but has huge benefits in the long term since you only have to package it once, and then all your applications can consume your saved models.
Serving models on Kubernetes
Enterprise computing is moving to Kubernetes, and Kubeflow has long been talked about as the platform to solve MLOps at scale.
KFServing, the model serving project under Kubeflow, has shown to be the most mature tool when it comes to open-source model deployment tooling on K8s, with features like canary rollouts, multi-framework serverless inferencing and model explainability.
Learn more about KFServing in What is KFServing?
Learn more about MLOps
Canonical provides MLOps & Kubeflow training for enterprises alongside professional services such as security and support, custom deployments, consulting, and fully managed Kubeflow – read Ubuntu’s AI services page for details.
Simplify your Kubeflow operations
Get the latest Kubeflow packaged in Charmed Operators, providing composability, day-0 and day-2 operations for all Kubeflow applications including KFServing.
Run Kubeflow anywhere, easily
With Charmed Kubeflow, deployment and operations of Kubeflow are easy for any scenario.
Charmed Kubeflow is a collection of Python operators that define integration of the apps inside Kubeflow, like
katib or pipelines-ui.
Use Kubeflow on-prem, desktop, edge, public cloud and multi-cloud.
What is Kubeflow?
Kubeflow makes deployments of Machine Learning workflows on Kubernetes simple, portable and scalable.
Kubeflow is the machine learning toolkit for Kubernetes. It extends Kubernetes ability to run independent and
configurable steps, with machine learning specific frameworks and libraries.
Install Kubeflow
The Kubeflow project is dedicated to making deployments of machine learning workflows on Kubernetes simple,
portable and scalable.
You can install Kubeflow on your workstation, local server or public cloud VM. It is easy to install
with MicroK8s on any of these environments and can be scaled to high-availability.
Newsletter signup
Related posts
Meet Canonical at KubeCon + CloudNativeCon North America 2024
We are ready to connect with the pioneers of open-source innovation! Canonical, the force behind Ubuntu, is returning as a gold sponsor at KubeCon +...
7 considerations when building your ML architecture
As the number of organizations moving their ML projects to production is growing, the need to build reliable, scalable architecture has become a more pressing...
AI in 2025: is it an agentic year?
2024 was the GenAI year. With new and more performant LLMs and a higher number of projects rolled out to production, adoption of GenAI doubled compared to the...